The Guitar Player's Resource
Most of us have heard the old joke: "A guitarist spends half his life tuning and the other half playing out of tune." When I hear this joke, I both laugh and wince. I wince because the joke expresses an uncomfortable truth; that is, far too many guitarists, regardless of playing ability, experience serious difficulty tuning. Why are tuning problems so common? I see two reasons. First, guitarists frequently lack the knowledge and skills needed for precise tuning; indeed, few of us receive systematic training in how to tune and, until recently, virtually no materials have been available for learning precise tuning skills. Second, as we shall see below, conventional tuning approaches are troublesome to use accurately. The unfortunate result of all this is that tuning is often a painful source of frustration for numerous guitarists and their listeners.
To tackle these problems, I started formulating a new tuning system in 1983, the year that I began teaching at the same university as Professor Owen Jorgensen, one of the world's leading authorities on the tuning of keyboard instruments and the training of keyboard technicians.1 Exposure to Prof. Jorgensen's work fueled my efforts to create a fresh, comprehensive approach to guitar tuning. After more than ten years of trials with prototype methods, my efforts culminated in 1996 when Mel Bay Publications released my 61-page book, Tuning the Guitar by Ear.2 In this article, I'll summarize my approach to tuning, offer some tuning tips and discuss how any guitarist can learn to tune with ease.
Fluent tuning involves specific skills. Understanding the nature of these skills enables us to overcome deficiencies. When we look closely at the act of tuning, we see that tuning a string by ear requires three actions: we play a reference pitch and an out-of-tune string; we listen to the sound and adjust the string into tune. Therefore, accurate tuning calls for three interdependent skills:
Playing clearly entails sounding the strings with a vivid, sustaining tone and also damping unplayed strings to prevent confusing sympathetic vibrations. The principle here is simple: the clearer the sound, the easier the tuning. Listening astutely centers on hearing the pulsating sounds called beats. As most of us are aware, beats occur when two sustaining pitches differ slightly. 3 Beating slows as two pitches are brought closer into unison; beating ceases when two pitches are identical. Listening for beats is the easiest and most precise way to tune; indeed, this is how piano technicians tune. Adjusting strings precisely requires sensitive control of each tuning knob. This is a very subtle skill: since the strings are of differing thickness and tension, each responds differently when its knob is turned. In summary, guitarists who know exactly how to play, listen and adjust are able to tune securely; those with underdeveloped tuning skills are not.
Let's consider our old friend (or nemesis), the 5th-fret method. Although it works perfectly in theory, the 5th-fret approach seldom produces rapid, precise results. This is partly due to errors being compounded as we tune from string to string. It's also because the 5th-fret method doesn't allow us to easily listen for beats as we adjust strings into tune; so instead, we listen for changes in pitch.4 Accuracy suffers because it's tricky to recognize very small differences in pitch, especially given the timbre disparities between strings. Thus, although the 5th-fret method is relatively easy to play, it makes listening and adjusting problematic. Many common tuning methods share a similar design: they employ fretted unisons or octaves, which prohibit listening for beats as we tune; therefore, such methods are difficult to use with swift, consistent accuracy. In other words, these methods are effective for determining whether strings are in tune, but they are awkward for adjusting strings.
Another common tuning method employs unisons produced with harmonics at the 5th and 7th frets. This approach facilitates listening for beats and allows us to adjust strings efficiently and precisely. However, few guitarists recognize that 5th and 7th-fret harmonics must not be tuned identically. For example, with a properly set up guitar, if we tune the 5th-fret harmonic of the fifth string and the 7th-fret harmonic of the fourth string to a beatless unison, the 4th string will play flat. This is because, unlike 5th and 12th-fret harmonics, 7th-fret harmonics are slightly sharp of their corresponding fretted pitches.5 To tune the above unison correctly, we must sharpen the fourth string to an exact beat rate. Therefore, when understood, this method is effective for adjusting strings; but since 7th-fret harmonics are not equivalent to any fretted pitches, this method is imperfect for determining whether strings are in tune.
All the above tuning approaches have merits and limitations; none is ideal on its own. If rapid, accurate tuning is to be accessible to every guitarist, we need alternative approaches that are fully effective and suited to differing playing levels. In designing a tuning method for beginning guitarists, ease of playing is essential; but if listening and adjusting are as difficult as with the 5th-fret method, beginning students won't be able to tune easily, if at all. The best tuning strategy for beginners is to simplify all three tuning actions. For experienced guitarists, however, ease of playing is less important, so we are best served by employing tuning procedures that produce the clearest possible sounds and that maximize tuning efficiency and precision--even if this requires more complex playing. My tuning system is designed according to these principles. It includes distinct beginning and advanced tuning methods and integrates these with instruction in guitar fitness and tuning theory. This holistic approach provides guitarists with the knowledge, skills and methods that allow optimal fluency with tuning.
My tuning strategy for beginning guitarists is twofold: to enable rapid, accurate tuning from the very first lesson, and to support prompt development of all tuning skills. I incorporate two concurrent methods: one entails tuning by ear; the other involves electronic tuning. To tune by ear, beginners use an approach I call matching open strings, where they tune their open strings to those of their teacher's guitar or to any other reliable pitch source (e.g., a digital recording of open strings). In a nutshell, this simple procedure involves sounding a reference pitch, after which a student plays the corresponding open string. The student lowers the string so that beating is clearly heard, and then raises the string to where beating stops.6 When beatless against the reference pitch, the string is in tune. This procedure is then repeated for each string. 7 As shown in my book, I train students to play open strings in a specific, accessible manner that produces a clear tone and dampens significant unplayed strings.8
Concurrent with string matching, I advocate electronic tuning because I've noticed a direct correlation between the consistent, early use of electronic tuners and facility in learning to tune by ear. I'm now convinced that, contrary to my prior assumptions, electronic tuning helps beginners develop important skills and habits needed for accurate tuning by ear. My view is that electronic tuning enables students to always play in tune and thereby habituate to the sound of in-tune guitars. What's more, electronic tuning boosts student confidence, promotes independence and cultivates precise tuning knob control. By combining electronic tuning and string matching, students quickly develop all three tuning skills, thus laying the technical and emotional groundwork for learning more advanced tuning methods.
My tuning method for experienced guitarists is designed for utmost tuning speed and precision. This approach is highly detailed and space limitations preclude a full description here, so I'll summarize the overall design and show the procedures for tuning two strings--complete instructions may be found in my book. In creating this system, my strategy was to enable listening for beats during all procedures, prevent the compounding of errors, and offer a coherent pedagogical plan. In due course, guitarists who use this method tune accurately in less than one minute, but achieving such fluency requires diligent study over several weeks. To simplify learning, I employ an incremental approach, first training guitarists to match open strings as described above. Next, they continue honing their tuning skills by practicing ten preparatory exercises. Once these are thoroughly assimilated, they learn the tuning procedures one string at a time. In the end, precise tuning is easy.
This system merges aspects of previously discussed tuning methods. For example, fretted unisons and octaves are ideal for determining whether strings are in tune, so I use these as tests of tuning accuracy. But to listen for beats while adjusting strings, the left hand must be free to turn the tuning knobs while two strings sustain; so for adjusting, I use only harmonics and open strings since these sustain without left hand involvement.
To begin the tuning process, we tune the 5th-fret harmonic of the fifth string to the A-440 from an electronic metronome (or any other reliable source). We sound the A-440 and the harmonic, damping the unplayed strings with the right-hand fingers. We lower the fifth string so that beating is clearly heard, then raise it to beatless. When beatless against the A-440, the string is in tune (figure 1).

Figure 1: Tuning the Fifth String
Next, we tune the fourth string by sounding the 5th-fret harmonic of the fifth string and the 7th-fret harmonic of the fourth string, damping the unplayed strings. The fourth string is lowered, then raised slightly sharp of beatless to beat at a rate indicated by a metronome setting (figure 2). I represent the sound of beats with the user-friendly syllables, "wah-ooh-wah-ooh." The metronome setting corresponds to one tick for "wah" and one tick for "ooh."9 It takes practice to tune these harmonics to a particular beat rate--the preparatory exercises included in my book enable us to perfect this skill prior to learning the tuning procedures.
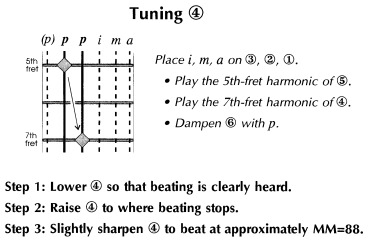
Figure 2: Tuning the Fourth String
To check our tuning accuracy, we immediately test the 4th string by playing the 12th-fret harmonic of the fifth string and the 7th-fret note of the fourth string, damping the unplayed strings (figure 3). If the fourth string is in tune, this unison will be beatless; if the string is out of tune, we repeat the tuning procedure (so that we're able to listen for beats while adjusting the string), and test again. The test is the final arbiter of whether the string is in tune.10 This combination of tuning and testing yields exceptional accuracy because it enables us to evaluate a string's tuning in more than one way.11
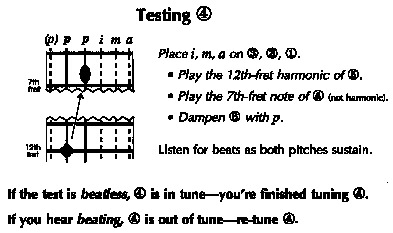
Figure 3: Testing the Fourth String
Each remaining string is tuned and tested in a similar fashion: we sound two pitches, one being a 7th-fret harmonic; we dampen the unplayed strings and adjust the out-of-tune string to a specific beat rate. The string is then immediately tested against the fifth string using a fretted unison or octave--testing each string against the same reference string prevents any compounding of errors. Finally, all strings are evaluated with specific test chords.12
My book includes instructions for three commonly used alternate tunings: low-D tuning, low-G tuning, and the Renaissance tuning where the third string is tuned to F#. Perhaps our most vexing alternate tuning problem is the 6th string going out of tune when we tune it back and forth from E to D. The string drifts out of tune because a sudden tuning change makes it unstable: when we lower the 6th string from E to D it goes slightly sharp; when we raise it from D to E it goes flat. In other words, the string creeps toward its previous tension level. The following procedures will compensate for this and greatly increase the string's stability.
Stabilizing the 6th string when tuning from E to D on a classical guitar
(1/2 turn = a 180 degree rotation of the tuning knob).
Stabilizing the 6th string when tuning from D to E on a classical guitar
Maintaining a fit guitar is vital for precise tuning. A poorly set up instrument will be impossible to tune accurately with any method. I've found that many guitarists are unaware of the significance of proper setup and therefore they sometimes struggle to tune guitars that, without repair, cannot be accurately tuned. Clearly then, a basic understanding of guitar setup is essential for security with tuning. Because of this, I teach simple guitar maintenance skills to my students, and my book begins with these same guitar fitness guidelines. These include strategies for replacing strings, looking after tuning gears, controlling humidity levels and a few other tips for assessing a guitar's overall condition. A simple test is included to check for accurate intonation. Setup flaws are quite common, even among expensive instruments, and all guitars require occasional adjustment. So if you're ever uncertain whether a guitar plays in tune, have it evaluated by a qualified technician.
Here, let's examine one crucial tuning concept: guitars are fretted in what's called equal temperament and as a result, all keys sound equally in tune (or equally out of tune, depending on your perspective). This equality is achieved through compromise; that is, some intervals are more in tune than others. For example, unisons and octaves are perfectly in tune and sound beatless--in fact, they are the only beatless intervals in equal temperament. Major thirds, on the other hand, are quite sharp and beat noticeably. This is why when we play an E-major chord in open position, the G# on the third string sounds sharp--it IS sharp and it's supposed to be. If we lower the third string to make the G# less sharp, the third string will sound flat for other intervals. Though it's possible to fret a guitar in any number of alternative temperaments, none of these have been widely adopted. Therefore, virtually every guitar in existence is fretted in equal temperament.13
The inherent complexities of equal temperament add to the widespread confusion about guitar tuning. Fortunately, extensive knowledge of tuning theory isn't required in order to tune well; we mainly just need to know how to tune. But some understanding of equal temperament and other concepts will add to our confidence with tuning. Accordingly, my approach to tuning pedagogy initially focuses on how to tune, but then I progressively introduce explanations of why tuning works the way it does. This blending of how and why contributes to building the reliable tuning habits that every guitarist needs. Ultimately, our tuning knowledge and sensitivity evolve to a point where we appreciate tuning and intonation as satisfying artistic elements of our overall musicianship.
Though tuning problems are common, they are nothing new--they've been handed down through generations of guitarists. Indeed, we perpetuate these problems whenever we fail to acknowledge tuning deficiencies or when we attribute them to causes beyond our control. Many guitarists, for example, mistakenly blame their tuning difficulties on a lack of talent and therefore feel powerless to improve. In truth, tuning problems result from a correctable lack of information and skill. By choosing a suitable tuning method, acquiring basic knowledge and skills, and maintaining a properly set up instrument, every guitarist can enjoy the rewards of accurate, pain-free tuning.
Notes:
1 See: Jorgensen, Owen, Tuning, (East Lansing: Michigan State University Press, 1991).
2 Klickstein, Gerald, Tuning the Guitar by Ear, (Pacific, MO: Mel Bay Publications, 1996). For additional information, please visit: www.melbay.com.
3 Beats are caused by the sound waves of two slightly differing pitches interacting in the eardrum. Though the two waves are of differing frequencies, periodically the wave crests or troughs will exactly coincide. When this occurs, the waves interact in two respects: 1) when the crest of one wave coincides with the trough of another, volume decreases because the two waves are trying to move the eardrum in opposite directions and these forces cancel each other out causing the eardrum to move less; 2) when either two crests coincide or two troughs coincide, volume increases because the waves support each other and move the eardrum more. As these two interactions alternate, we hear a regular, pulsating change in volume (and timbre).
4 With the 5th-fret method, we can hear beats when we play a 5th-fret pitch and an open string; but when the left hand leaves the fingerboard to turn a tuning knob, only one pitch remains sounding, so beating can't occur. Therefore, as we adjust an out-of-tune string, we're hearing changes in pitch rather than changes in beat rate.
5 For an explanation, see: Dolata, David, "The Secret of Tuning by Harmonics," (Soundboard XIX/4, Spring 1993, 27-37).
6 When tuning with any method, guitarists should always raise, and never lower strings into tune; raising into tune removes slack from the tuning mechanism and helps a string stay in tune.
7 I also use this string-matching method for tuning guitar ensembles, where each guitarist in a group tunes his or her open strings to those of a single accurately tuned reference guitar.
8 Elementary string damping is appropriate for beginners, however, I train experienced guitarists to dampen all five unplayed strings when matching each open string; see: Tuning the Guitar by Ear, pages 38-41.
9 The tuning beat rates given in the instructions are all approximate. Universally accurate beat rates cannot be provided because guitars vary in their setup; however, the rates fluctuate little from one properly set up guitar to another. In addition, the actual pitches produced when we play harmonics differ somewhat from the theoretically derived pitches of the harmonic series. Therefore, I determined the given beat rates by tuning numerous properly set up guitars and averaging the results.
10 Once the test is beatless, we're able to determine the exact beat rate for tuning the string by playing the pitches used for tuning, listening to the beats, and memorizing the feel of the beat rate.
11 Nearly all tuning methods involve tuning and testing. With the 5th-fret method, for example, when we play a 5th-fret pitch and an open string, we're testing; when we remove the left hand from the fingerboard and turn the tuning knob, we're tuning. With the 5th-fret method, we can listen for beats when testing, but not when tuning.
12 The basic test chords are third-less versions of the five open-position major forms; see: Tuning the Guitar by Ear, pp. 34-35.
13 For additional information regarding equal temperament, see Dolata, op. cit.
Classical guitarist Gerald Klickstein performs and teaches throughout the U.S., appearing as solo recitalist, chamber musician and clinician.
He is a member of the distinguished artist-faculty of the North Carolina School of the Arts where his students consistently win top prizes in a variety of guitar competitions. His writings and musical arrangements are published by Mel Bay Publications, Southern Music Company and Tuscany Publications.
